
Ketika kami (tim infra) ingin menaikkan resource dan menekan pricing di saat yang sama, maka terpikirkan salah satu solusi termudah adalah dengan menggunakan spot instance untuk menjalankan service-service di eFishery.
Namun kata “termudah” ini tentu tidak membuat proses ini menjadi mudah, kami telah menghabiskan waktu dan resource yang cukup lama sebelum akhirnya menentukan skematik desain terbaik (so far) dari penggunaan ini.
Apa itu Spot Instance?
Definisi Spot Instance dari https://aws.amazon.com/id/ec2/spot/
Instans Spot Amazon EC2 memungkinkan Anda memanfaatkan kapasitas EC2 yang tidak terpakai di AWS cloud. Instans Spot tersedia dengan diskon hingga 90% dibandingkan dengan harga Sesuai Permintaan. Anda dapat menggunakan Instans Spot untuk berbagai aplikasi yang stateless, toleran terhadap kesalahan,atau fleksibel seperti big data, beban kerja terkontainer, CI/CD, server web, komputasi kinerja tinggi (HPC), serta beban kerja pengujian & pengembangan
Spot Instance pada dasarnya adalah, resource yang tidak terpakai pada AWS cloud, yang mana resource tersebut sewaktu-waktu dapat diambil kembali oleh AWS sesuai kebutuhan.
Makna dari “diambil kembali” adalah, mesin tersebut akan dimatikan dan dihapus dari sistem AWS kita, dan ini bisa terjadi kapanpun
Strategi penggunaan
Adanya limitasi bahwa instans akan hilang, membuat kami harus memiliki suatu sistem pada infra dengan spesifikasi
- Node Self-Healing Adanya spot fleet dengan ekspektasi jumlah node yang diinginkan, sangat membantu proses ini
- App Self-Recovery Semua service yang hilang akibat hilangnya instans terkait, dapat dijalankan lagi di node yang baru secara otomatis
- Disaster Recovery Ada saatnya spot instance tidak dapat memberikan mesin yang cukup.
Mekanisme self healing pada node
Berikut adalah salah satu konfigurasi spot fleet yang kami punya
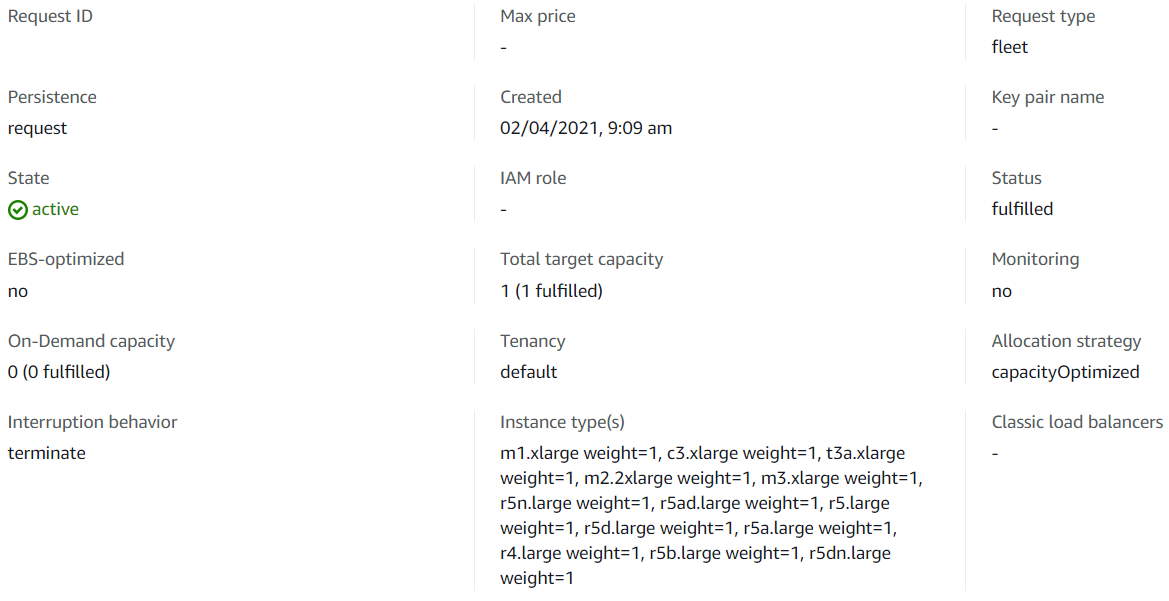
Ketika kami melakukan request terhadap spot fleet, hal yang terpenting adalah ketika memilih jenis instans yang diperbolehkan jalan dan jumlah node yang diinginkan. Semakin banyak jenis instans yang dipilih tentu semakin baik.
Terlihat pada request ini, kami mengeset jumlah nodenya ke 1, yang akan memastikan spot fleet ini menjalankan tepat 1 instans. Apabila 1 instans tersebut dimatikan oleh AWS, maka spot fleet akan mencarikan penggantinya sebanyak jumlah node yang dimatikan (dalam hal ini 1).
Mekanisme self recovery pada app
Oke, masalah node mungkin sudah aman ketika kita menggunakan spot fleet. Namun, bagaimana dengan app yang hilang?
Disini peran orchestrator nomad muncul, ketika suatu node hidup, kami memiliki startup script otomatis untuk menjalankan nomad agent, yang akan terdeteksi secara otomatis oleh nomad server. Seluruh alokasi dan jumlah node yang berjalan dapat dilihat statusnya di laman ini.
Selama tidak semua instans hilang di saat yang sama, maka hilangnya 1 atau 2 instans tidak akan membuat service kami terganggu. Bahkan, apabila instans yang hilang dapat digantikan dengan cepat oleh AWS dalam hitungan menit, kami pun tidak akan merasakan efeknya sama sekali.
Cost Benefit
Keuntungan terbesar menggunakan spot instance adalah potongan harga yang ditawarkan dapat mencapai 90% harga normal, cukup sebanding dengan resiko yang ada. Berikut adalah pricing salah satu spot fleet kami
Disaster Recovery
Pada dasarnya, menggunakan spot instance itu sama saja mengundang masalah ke sistem Infra, karena memang begitulah sifat dari instans tersebut.
Karena itu, kami sudah memiliki pacuan apabila disaster terjadi. Berikut adalah kemungkinan disaster dan solusinya
- Spot Instance hilang semua Kami memiliki spare server di on-demand, diutamakan untuk container database. Sisanya tinggal menunggu waktu untuk node yang baru
- Tidak adanya node yang baru Kami juga memiliki startup script untuk menjalankan nomad agent, untuk dijalankan di instans on-demand. Hanya membutuhkan waktu ~5 menit sampai akhirnya diterima oleh nomad server, dan tambahan waktu ~15 menit untuk menjalankan semua app yang hilang tersebut. Dan ini dapat dilakukan secara paralel apabila jumlah nodenya lebih dari 1.
- File system database corrupt So far, belum pernah kejadian seperti ini, walaupun kami telah kehilangan beberapa instans. Namun apabila terjadi hal seperti ini, kami punya snapshot dalam bentuk cold backup (file) dari seluruh database yang berjalan pada sistem nomad. Dengan tambahan, ada beberapa database yang sudah memiliki sistem master-slave replica.
Epilog
Sekali lagi, penggunaan spot instance sama seperti halnya hidup di daerah gunung vulkanik aktif. Daerah tersebut bisa menjadi subur (src: https://theconversation.com/letusan-gunung-agung-bisa-menghasilkan-tanah-tersubur-di-dunia-85142), namun harus siap apabila bencana seperti gempa bumi dan gunung meletus terjadi.
Dan kami pun selalu berupaya untuk memikirkan BCP (Business Continuity Planning) dan DR (Disaster Recovery) bukan hanya untuk spot instance, namun untuk semua kemungkinan yang akan terjadi.